Keywords: Python, Machine Learning, ML, algorithms, gemmological analysis
Introduction
Python, a powerful programming tool with extensive scientific computing capabilities, is being increasingly utilized in gemmological science. It is particularly well-suited for processing and analyzing spectroscopic data, which is crucial for various machine learning (ML) applications in gemmology. By leveraging ML algorithms and models, Python can automate time-consuming tasks, reduce human error, and enhance the overall efficiency of gemmological analysis and identification. This article will provide a general overview of how Python processes and analyzes spectroscopic data, highlighting its significance in ML-based gemmological data modeling.
Why Python?
Python is a popular high-level, interpreted programming language known for its strong code abstraction, making it easily understandable for humans. It has gained wide acceptance in various domains, including data science, artificial intelligence, and scientific computing. Python’s modularity is a significant advantage, allowing users to import and utilize pre-existing code through packages and libraries designed for specific tasks. Its extensive library ecosystem makes Python suitable for diverse scientific applications, such as analyzing large datasets, creating informative visualizations, and developing advanced models. In scientific disciplines like earth science, geology, and gemmology, Python’s versatility shines. Noteworthy libraries that enhance Python’s scientific capabilities include:
- NumPy: Supports large arrays and mathematical functions for efficient spectroscopic data manipulation.
- SciPy: Provides modules for optimization, signal processing, linear algebra, and spectral deconvolution.
- Pandas: Simplifies analysis of large datasets with data structures like DataFrames and Series.
- Matplotlib: A plotting library for creating static, animated, and interactive visualizations, such as line and scatter.
- Scikit-learn: Tools for predictive modeling, ML algorithms for gemmological determination and classification.
Machine Learning for Gemmological Applications
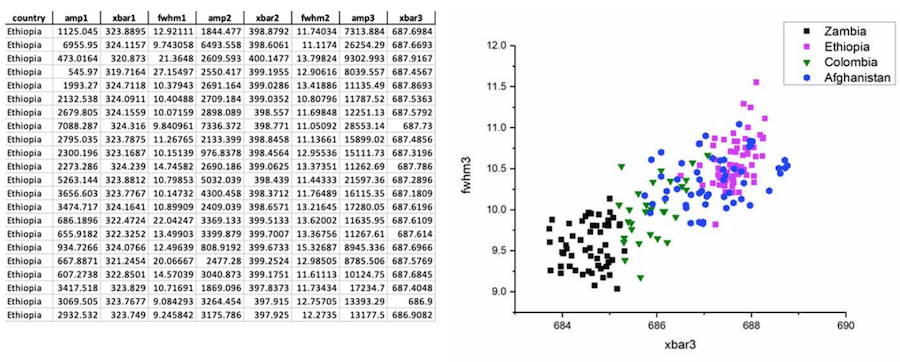
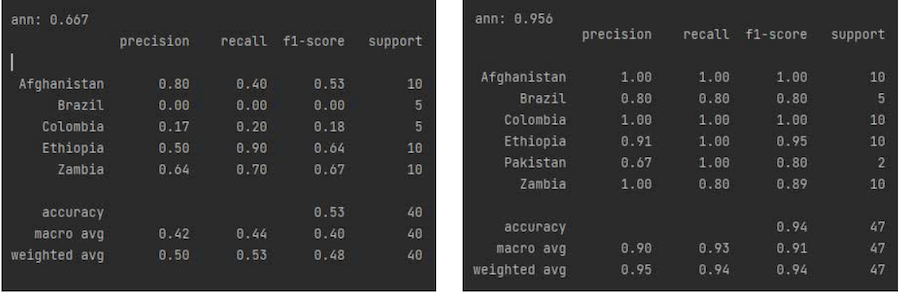
ML provides an alternative to conventional identification methods that mostly rely on expert knowledge and experience alone. ML algorithms can learn and recognize distinctive properties and characteristic features of gemstones (Wang & Krzemnicki, 2021; Wanthanachaisaeng et al., 2022), such as trace element concentrations and spectral data. For example, to determine the country of origin of emeralds, trace element analysis can be employed, focusing on clustering patterns among elements such as K, V, Cr, Fe, Rb, and Cs. Additionally, the analysis of emerald treatment primarily relies on identifying characteristic peaks within the 2700-3200 cm-1 range of FTIR spectra. Support Vector Machines (SVM), Decision Trees & Random Forests, K-Nearest Neighbors (KNN), and Neural Networks & Deep Learning are examples of supervised learning algorithms, where models are trained using labeled data with known outputs to make predictions on new, unseen data. On the other hand, Principal Component Analysis (PCA) is an example of unsupervised learning, where models are trained on unlabeled data to discover hidden patterns, structures, or relationships.
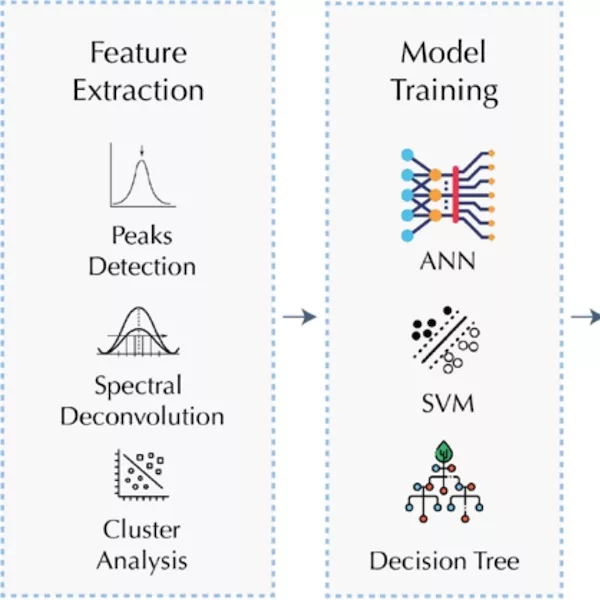
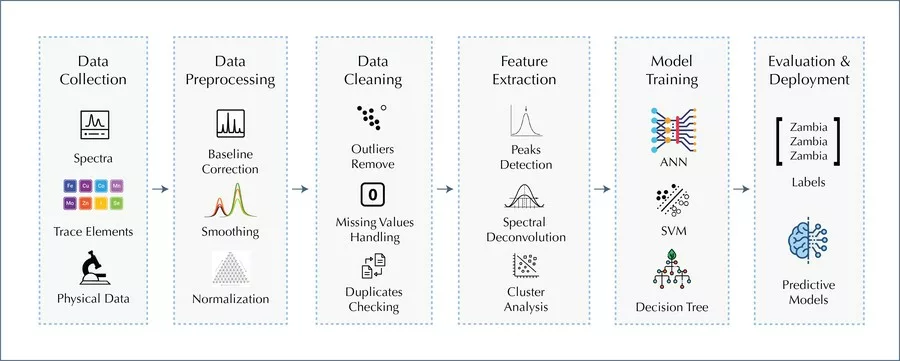
Examples of Gemstone Analysis Process using Python and Machine Learning
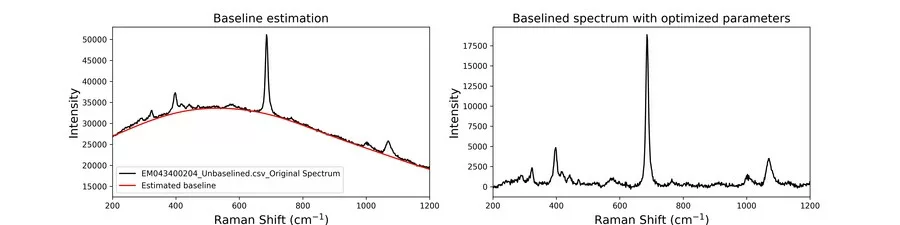
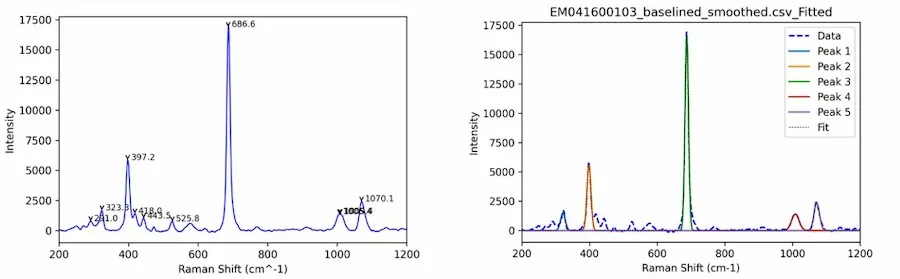
This section provides guidance on the typical steps in analyzing and modeling gemmological spectroscopic data using Python. The process involves data collection, preprocessing, cleaning, and feature extraction, followed by Let’s begin by examining the first step of the process: (1) Data collection: Digital raw data from techniques like Raman, FTIR, EDXRF, and trace elements are collected and stored in various file formats such as CSV, ASCII, or TXT. Python libraries like Pandas, NumPy, and SciPy, can read, manipulate, and combine these files into the desired format, preparing them for pre-processing and analysis. model training, evaluation, and deployment. It is important to note that analyzing and modeling gemmological spectroscopic data can vary depending on the dataset, research question, and intended application. Thus, the examples in this section are a general guide rather than a rigid set of rules. Figure 1 provides an overview of the entire process.